Understanding Language Beyond Words: Building IdiomX for Multilingual AI and Idiom Interpretation


Understanding Language Beyond Words: Building IdiomX for Multilingual AI and Idiom Interpretation
By Ayman Sharara, DSTI School of Engineering student in MSc in Data Science & AI, developed IdiomX as part of his Deep Learning project, a large-scale multilingual dataset designed to help AI understand idioms, retrieve figurative expressions, and interpret hidden meaning across languages.
When Language Stops Being Literal
What does “spill the tea” mean? (Not a kitchen disaster)
Idioms are expressions where words do not mean what they say, and that is exactly where AI starts to struggle.
Humans understand them naturally. Machines… not so much.

The Problem
Most existing idiom datasets are small, limited, not multilingual, and focused on simple tasks. In short, they do not reflect how people communicate.
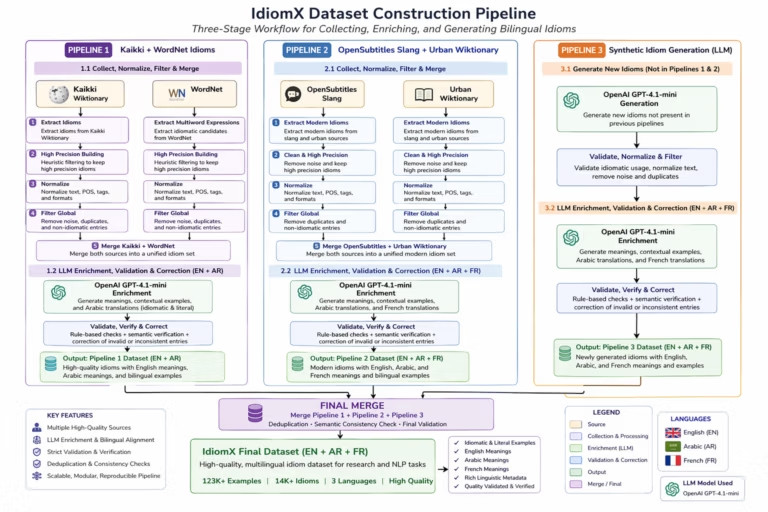
Building IdiomX (190K+ examples) : Step by Step
IdiomX was built through a structured and scalable pipeline:
- Collection: extracting idioms from sources such as Wiktionary and WordNet, along with generating additional candidate idioms to improve coverage.
- Cleaning and Normalization: filtering noise, deduplication, and standardizing expressions
- LLM Enrichment: using OpenAI GPT-4.1-mini to generate meanings, contextual examples, and multilingual translations (English, Arabic, French).
- Validation: combining semantic similarity scoring and rule-based checks to ensure consistency and quality
The pipeline is modular and extensible, making it easy to scale to new languages and add richer annotations.
The full workflow was implemented using Python, combining data engineering pipelines with LLM-based enrichment and validation to ensure reproducibility and scalability.
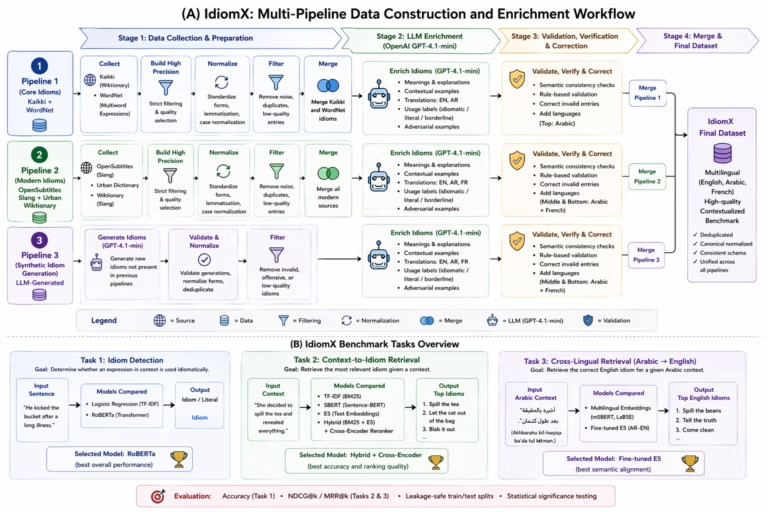
More Than a Dataset: A Multi-Task Benchmark
IdiomX supports multiple tasks:
- Task 1: Idiom Detection
TF-IDF + Logistic Regression vs DistilBERT vs RoBERTa, with RoBERTa selected for strong contextual understanding. - Task 2: Context-to-Idiom Retrieval
Dense retrieval vs hybrid retrieval with reranking, where hybrid + fine-tuned reranker achieved the best performance. - Task 3: Cross-Lingual Retrieval (Arabic to English)
Multilingual embeddings compared to fine-tuned E5, with fine-tuned E5 showing strongest semantic alignment. - Task 4: Idiom Interpretation
Given an idiom or idiomatic sentence, the system retrieves its meaning in English, Arabic, and French. Hybrid retrieval with reranking produced the strongest interpretation performance.
Models were trained and evaluated on structured train and test splits with careful data selection to avoid leakage and ensure reliable benchmarking. The workflow spans raw data collection, model training, retrieval benchmarking, idiom interpretation, and deployment-ready artifacts.
Beyond these tasks, IdiomX can support chatbots, translation systems, idiom explanation assistants, language learning tools, sarcasm detection, and human-interacting robots.
Why It Matters Language is not just words, it is meaning, context, and sometimes sarcasm. If AI is going to understand humans, it needs to know that “break a leg” is encouragement, not a medical emergency. The project was developed using modern NLP and deep learning tools, integrating transformer models, embedding techniques, and retrieval architectures.
Idiom Interpretation Example
- “Spill the tea”
- English: reveal gossip
- Arabic: كشف الأسرار
- French: révéler des potins
This reinforces Task 4 instantly.
Conclusion
IdiomX helps move AI beyond literal language toward real understanding.
It is a step toward making machines interpret language the way humans actually use it.

Commentaires0
Veuillez vous connecter pour lire ou ajouter un commentaire
Articles suggérés